1. DOM(Document Object Model, 돔)
- 웹 문서의 모든 요소를 자바스크립트를 이용하여 조작할 수 있도록 객체를 사용해 문서를 해석하는 방법
- 웹 문서의 텍스트, 이미지, 표 등 → 객체
- document를 사용하면 자바스크립트에서 웹 문서 소스를 전부 인식할 수 있음(document는 수많은 DOM 요소 중 하나)
2. DOM 트리
- 문서 노드(Document Node): 트리의 최상위, DOM tree에 접근하기 위한 시작점
- 요소 노드(Element Node): HTML 요소를 표현, HTML 노드는 중첩에 의해 부자 관계를 가짐
- 어트리뷰트 노드(Attribute Node): HTML 요소의 어트리뷰트를 표현, 해당 어트리뷰트가 지정된 요소의 자식이 아니라 해당 요소의 일부로 표현
- 텍스트 노드(Text Node): HTML 요소의 텍스트를 표현, 요소 노드의 자식이며 자신의 자식 노드를 가질 수 없음, DOM tree의 최종단
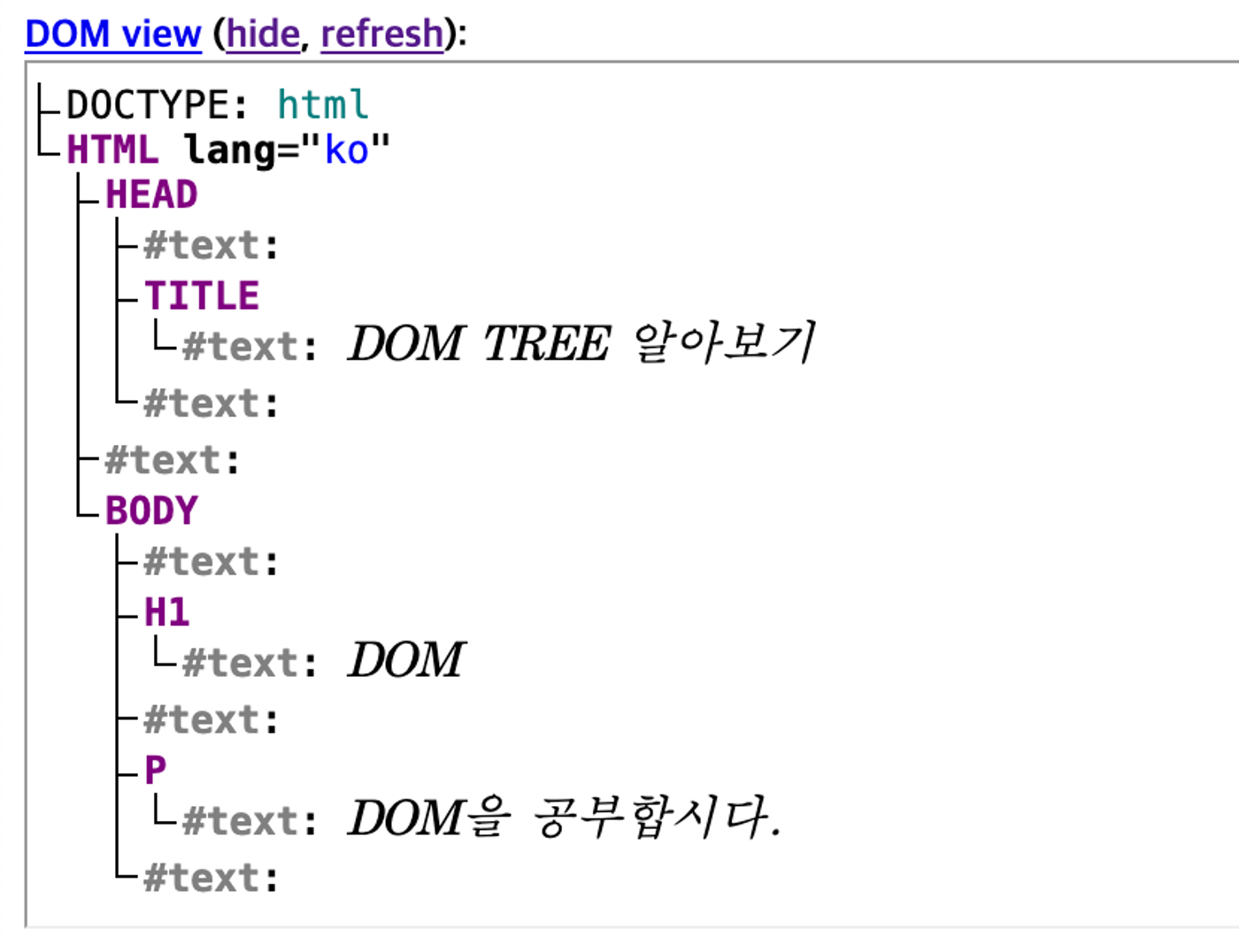
3. DOM 요소에 접근하기
- 자바스크립트로 DOM 요소에 접근할 때 → ‘선택자’ 사용
1) getElementById()
- id 선택자로 접근하는 함수

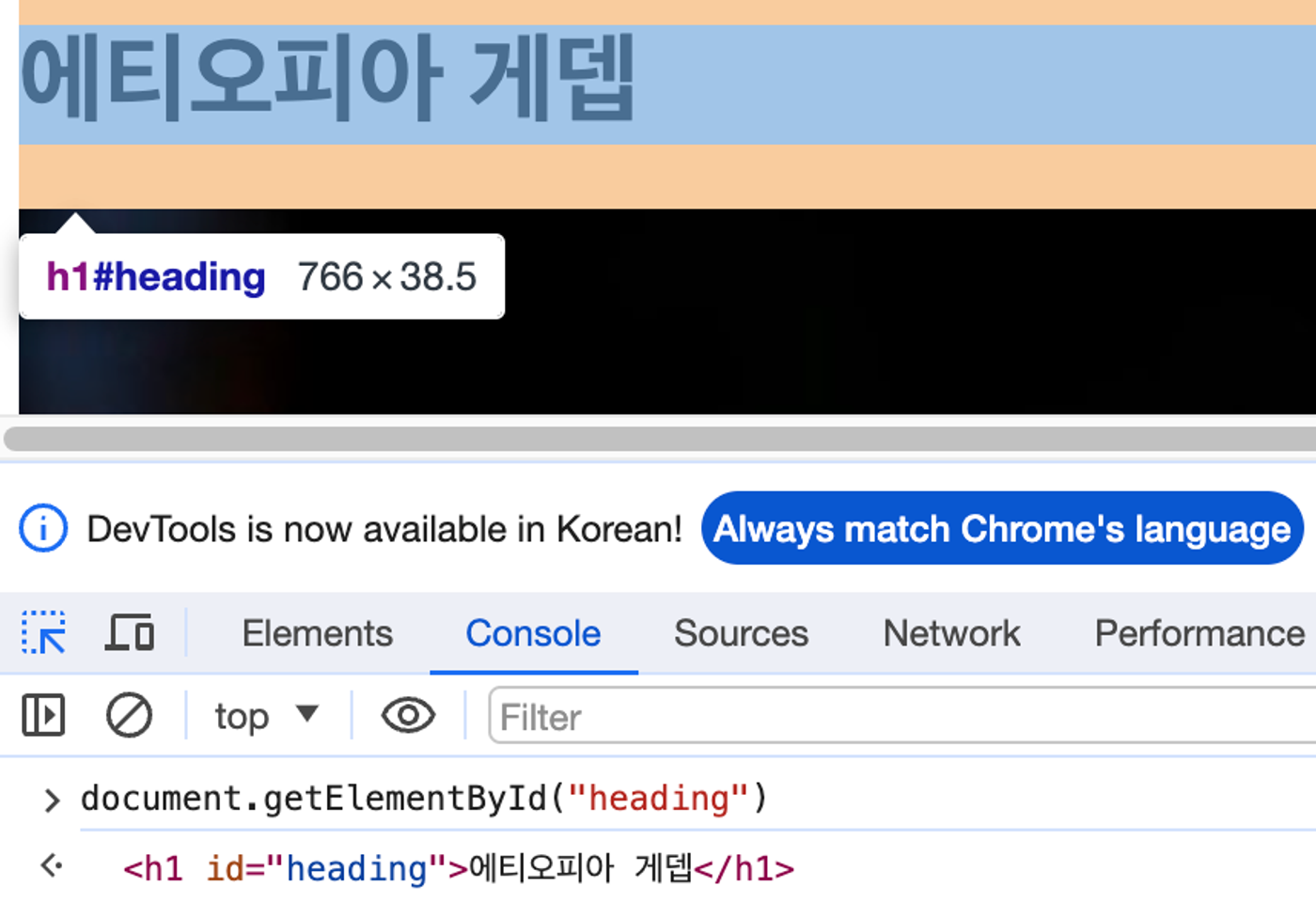
2) getElementsByClassName()
- class값으로 찾아내는 함수
- id 선택자와 다르게 웹 문서 안에서 여러 번 사용할 수 있음
- 2개 이상의 웹 요소에 접근

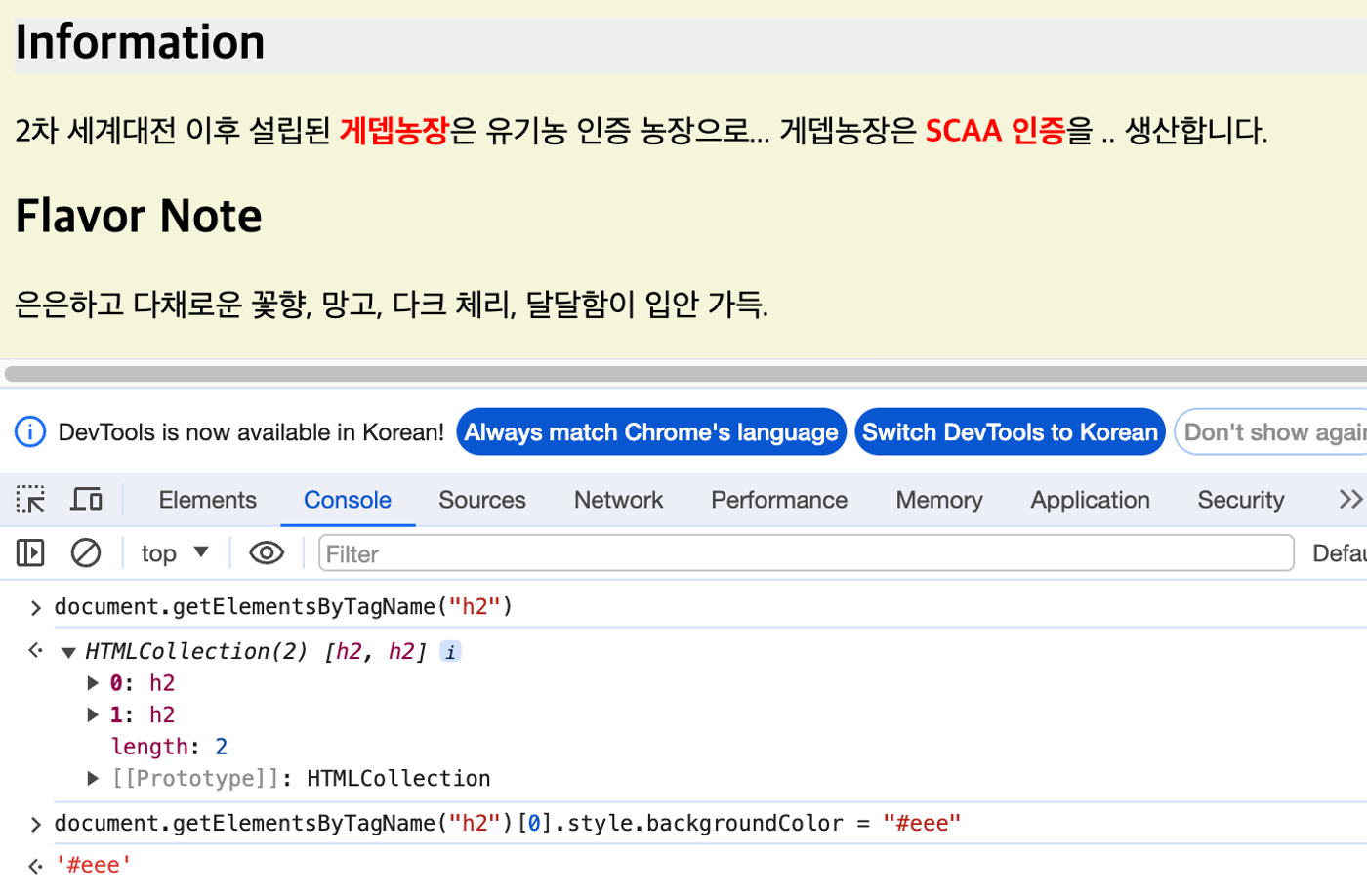
3) getElementsByTagName()
- id나 class 선택자가 없는 DOM 요소에 접근
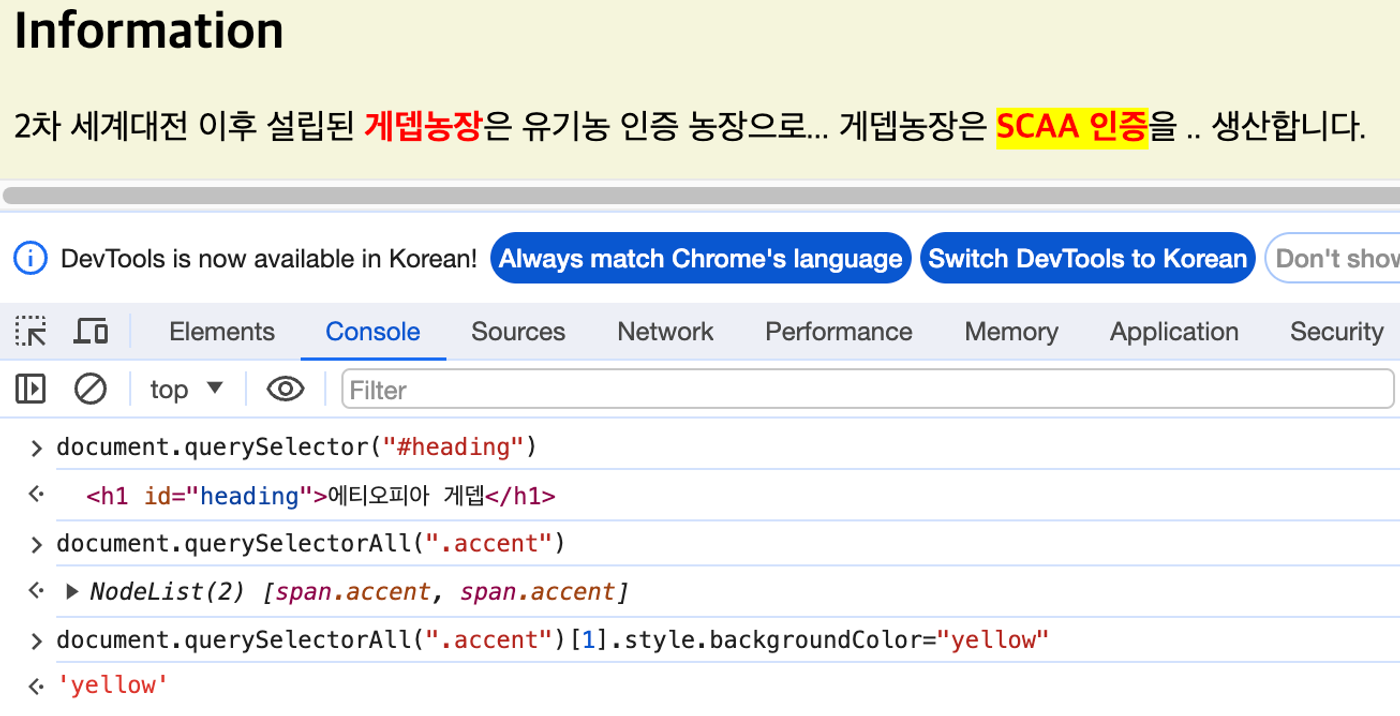
4) querySelector(), querySelectorAll()
- DOM 요소를 다양한 방법으로 찾아주는 함수
- id, class 값을 사용해도 되고 태그 이름을 사용해도 됨
- class 값 앞에는 마침표(.), id 값 앞에는 샵(#)을 붙임, 태그 이름은 기호 없이 태그 이름만 사용
*참고
- Do it! 자바스크립트 입문
- https://poiemaweb.com/js-dom
'오공완' 카테고리의 다른 글
| 정처기 3과목: 데이터베이스 (0) | 2024.02.22 |
|---|---|
| 정처기 3과목: 자료 구조 (0) | 2024.02.21 |
| 스프링 부트3 시작하기 (0) | 2024.02.05 |
| 231121 오공완 (0) | 2023.11.21 |
| 231120 오공완 (0) | 2023.11.21 |